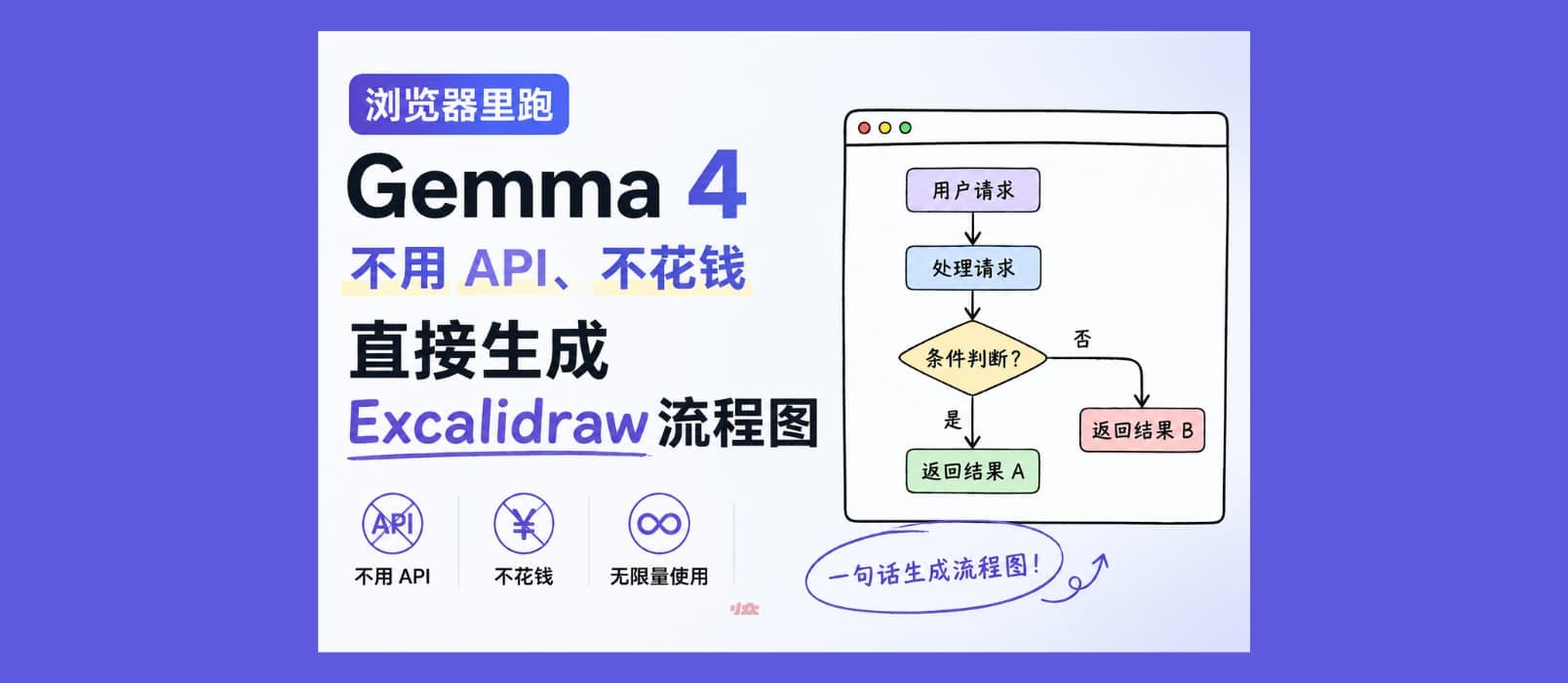
浏览器端运行Gemma 4:无需API,免费无限量绘制Excalidraw流程图
无需安装额外软件,只需下载3.1GB的Gemma 4 E2B大模型,并使用桌面版Chrome 134+版本,即可在浏览器中运行Gemma 4模型,并使用AI绘制Excalidraw流程图。
如今,手机上运行Gemma 4大模型已不再新鲜(iPhone、安卓现在就能跑 Gemma 4 了),现在连浏览器也能轻松实现。@Appinn
开发者利用Google最新提出的TurboQuant算法,将Gemma 4模型嵌入浏览器中,实现本地运行。
直接打开网页,即可在Excalidraw中使用AI绘制图形,整个过程均在本地完成,无需调用在线模型,也不消耗任何Token。
唯一要求是下载3.1GB的Gemma 4 E2B大模型,并确保使用桌面版Chrome 134+版本。

使用方法
直接打开以下网页:
输入中文即可生成完整的流程图,无需手动绘制框和连线。
性能表现
- 速度:每秒生成约24个token
- 端到端速度(end-to-end):每秒约22.7个token(包括准备、计算等)
- 输出长度:本次生成747个token
- 总耗时:32.9秒
- KV Cache:15.5MB / 37.0MB
- 当前上下文长度:2106 pos(模型已“记住”的token数量)
KV Cache从原本约37MB压缩到约15MB左右(约2.4倍压缩)。
需要注意的是,这样一个简单的例子需要37MB的KV Cache,青小蛙也是第一次感受到。
TurboQuant是什么?
TurboQuant是Google最近推出的新算法,可以将KV Cache中的向量压缩6倍,并可以直接搜索压缩数据,无需解压缩。

这样大模型就可以记住更长的上下文,回答更长的对话,也更不容易“忘记前面说过的话”。
- KV Cache:大模型在对话时用来“记住前面内容”的一块临时记忆。
- 向量:大模型理解文字的方式:我们对AI说话,会先被转换成一串数字,然后才能让大模型理解,这些数字,就是向量。
意义何在?
像Excalidraw这样的应用,以前接入AI一般需要调用在线大模型,按token付费。
现在换一种方式:
- 下载模型,在本地浏览器中运行
- 无需联网调用模型
- 不消耗Token,可无限量使用
这样一来,使用成本大大降低。